上一篇提到,網頁爬蟲就是讓爬蟲程式定期幫你Google。
為了更好地理解爬蟲的運作原理,這一篇我們要簡單說明一下網頁背後的工作原理。
在使用瀏覽器時,其實背後都是透過HTTP協定進行溝通。
常見的HTTP請求方法包括:
在爬蟲開發中,GET請求最為常見,因為大部分爬蟲需要從網頁中提取數據。
說明前,讓我們直接舉例
以iT邦幫忙官網和Chrome瀏覽器為例,我們可以通過「檢視網頁原始碼」來理解網頁結構。
例如,如果你想爬取發文者的標題,可以使用以下資訊來定位它: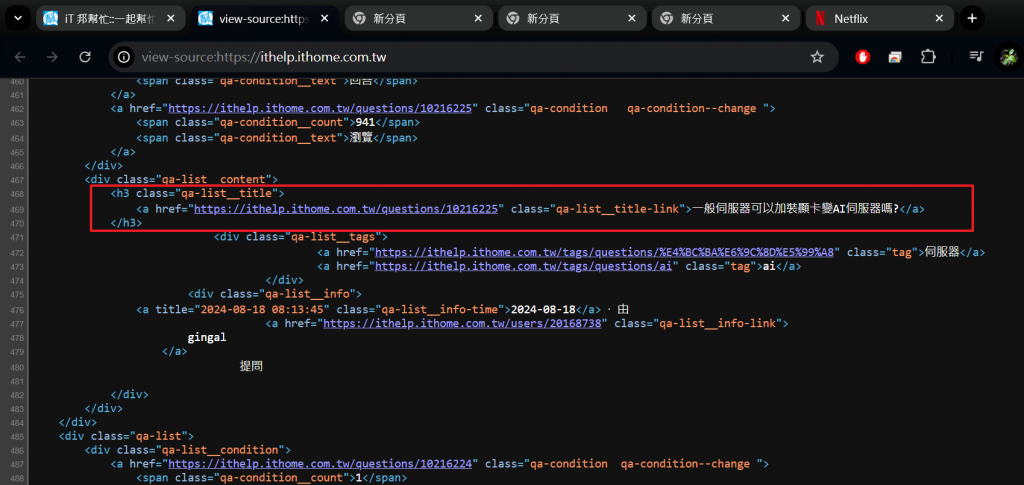
只要能看到想要的資訊,後面只要解析格式,就能夠提取資訊了。
進入開發者工具後,可以看到網頁的HTTP請求相關資訊。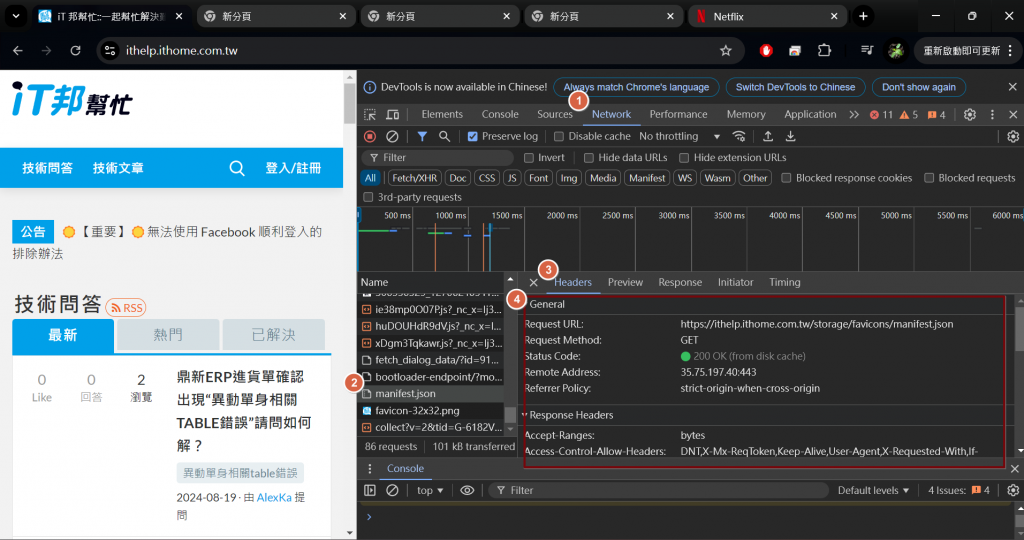
如上圖,可以看到瀏覽器背後使用了甚麼URL,並且執行的HTTP請求方法為何(圖中為GET)。
有上述的認知,其實已經就可以進行爬蟲程式的開發了。
但現代很多網頁使用JavaScript動態載入數據,這些數據不會直接出現在HTML源碼中,而是透過JavaScript向伺服器請求並插入到網頁中。
以591租屋網為例。
我們一樣右鍵,檢視原始碼。
當你在網站上搜尋房屋時,即使你在瀏覽器中檢視原始碼,也不會直接看到房屋資訊。
因為這些數據是透過動態加載獲取的。
例如,雖然網頁上顯示了1409個房屋資訊,但在原始碼中卻看不到任何相關信息,這就是動態加載導致的現象。
但是即使是動態加載的網頁,爬蟲程式一樣有辦法解決,先靜待後面的更新。
今天,我們探討了HTTP請求的基本概念,了解了如何通過瀏覽器工具來查看網頁結構,並討論了動態加載的特性。
明天預計深入了解591租屋網,以利後面的程式開發。


 iThome鐵人賽
iThome鐵人賽